El oído musical de las máquinas recorta la distancia que le separa de la visión artificial
Etiquetado automático de canciones y separación de voz e instrumentos son algunas de las aplicaciones del campo, que comienza a salir de la sombra de sectores más populares
“Por desgracia, y por decirlo en pocas palabras, el campo de la inteligencia artificial (IA) tiende a sobresimplificarse de la siguiente manera: IA es igual a deep learning, que es igual a visión artificial”. Son palabras escritas por el investigador en Ingeniería de Sonido Jordi Pons en su tesis, que acaba de ser reconocida con uno de los premios de investigación informática SCIE-Fundación BBVA, en la categoría de investigadores jóvenes informáticos. Ese esquema, marcado por las ramas de investigación más populares, dejaba fuera el sonido y los consiguientes avances en escucha artificial (machine listening), al menos hasta hace poco. “Aunque las tecnologías no son aún perfectas, ya nos permiten hacer algunas cosas que antes se consideraban imposibles”, señala Pons.
Entre los hitos conquistados figuran las investigaciones de este ingeniero en materia de etiquetado automático de canciones, el tema central de su tesis. “Es una forma de estructurar bases de datos de tal manera que puedes clasificar grandes colecciones para hacer recomendaciones o búsquedas”, explica. Otra línea de trabajo de Pons es la separación de fuentes, que permite descomponer una canción en los sonidos que la componen, por ejemplo, haciendo sonar por un lado la voz de Paul McCartney y por otro su piano mientras los Beatles interpretan Let It Be. “Por primera vez se pueden comercializar autokaraokes, por ejemplo. Que parece una tontería, pero en Japón hay muchos aficionados a este entretenimiento. O igual sacar un solo de batería o de guitarra para practicar encima de tu canción favorita”, comenta el investigador.
¿Cómo escucha una máquina?
Durante años, el funcionamiento de sus orejas se fue derivando de los otros campos pioneros en el desarrollo de habilidades artificiales, como el de la visión y el procesamiento del lenguaje natural. “La primera forma de tratar de desarrollar tecnologías basadas en este concepto fue adaptarlas directamente. Tomamos la arquitectura de visión por computador y la aplicamos directamente al audio”, precisa Pons. No en vano, el círculo virtuoso de investigación y financiación de los campos más aventajados daba como resultado una mayor disponibilidad de desarrollos y tutoriales de sistemas de este tipo. “Las comunidades de visión por computador y speech recognition han sido históricamente muy grandes. Esto significa que las empresas normalmente están interesadas en sus temas. En el caso de la música, muchas veces se dice que al no haber tanta industria digital, la comunidad siempre ha sido más pequeña. Como no hay dinero, no hay tantos investigadores que hagan esto”.
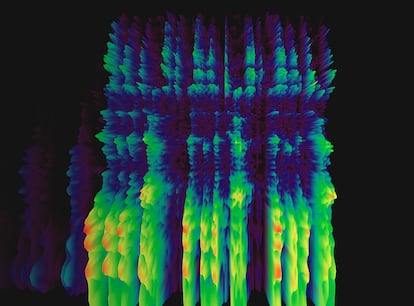
Así, los abundantes algoritmos de visión artificial resultaron moderadamente efectivos a la hora de interpretar el sonido cuando este adoptaba un formato visual: el espectrograma. Pero lo hacían con las obvias limitaciones de usar una herramienta para un propósito distinto de aquel para el que fue creada. “Estas representaciones tienen un significado distinto al de una imagen, que es espacio en sí. En un espectrograma hay dos dimensiones, tiempo y frecuencia, que no tienen nada que ver con el espacio”, subraya el experto. Diseñar las redes neuronales para interpretar toda esta información es lo que abre la puerta a nuevas perspectivas para el campo de la escucha artificial
¿Qué hace falta para que estas líneas de investigación se pongan al nivel de sus predecesoras? Datos. En el caso de la visión artificial, ImageNet ha sido un recurso clave para los avances del campo. Esta base de datos, integrada por más de 14 millones de imágenes con sus correspondientes descripciones, ha estado a disposición de los investigadores desde 2009. “En audio aún no tenemos algo así”, sentencia Pons. Pero hay proyectos en marcha. “Esto ha sido una parte importante de mi tesis, donde con mis compañeros del Music Technology Group de la Universitat Pompeu Fabra hemos tratado de anotar un dataset -conjunto de datos- muy grande, y todo con licencias abiertas para que todo el mundo pueda entrenar sus modelos y ver si podríamos avanzar un poco el estado de la cuestión”, continúa.
Los cimientos de este proyecto se pusieron en 2005, en la base de datos bautizada como FreeSound, que Pons describe como la web principal para compartir sonido online con licencias libres: “Hay una comunidad muy grande, que pone al grupo en la posición de crear bases de datos abiertas, libres y para toda la comunidad científica”. Esto no es moco de pavo, en un ámbito donde las licencias son una barrera constante. “Compartir sonidos, en general, es un poco complicado legalmente”, añade Pons. Y si hablamos de música comercial, las posibilidades son aún más limitadas: “No existen. Por eso, construir un dataset con licencias libres para el campo de audio y música es fundamental”.
Puedes seguir a EL PAÍS TECNOLOGÍA RETINA en Facebook, Twitter, Instagram o suscribirte aquí a nuestra Newsletter.